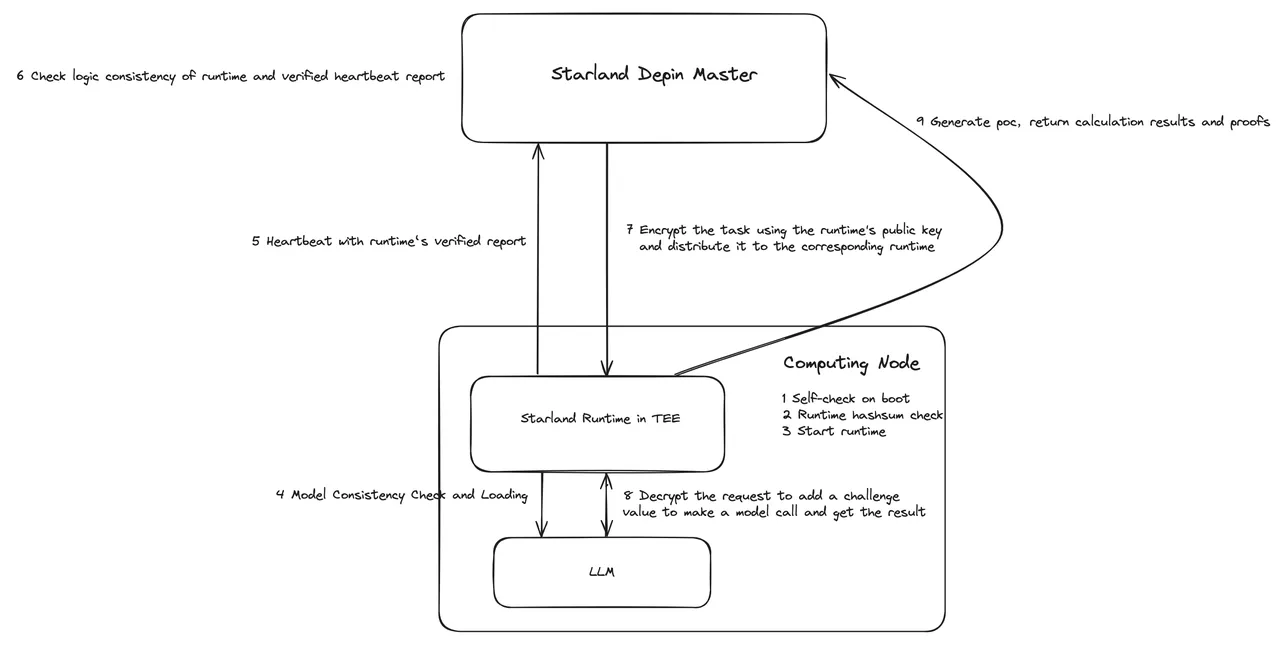
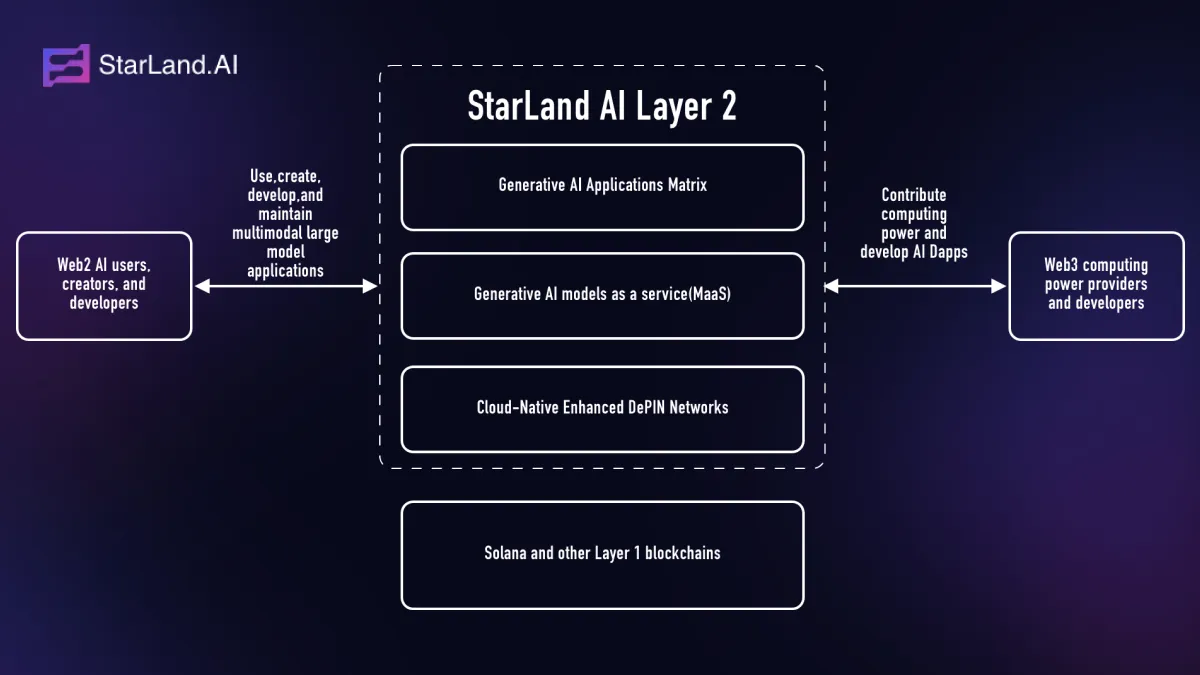
How does StarLandAI Enhance Machine Learning Model efficiency?


The advent of Large Language Models (LLMs) has marked a new era in the field of machine learning, bringing with it unprecedented capabilities for natural language processing. However, these models’ size and complexity pose significant challenges in terms of deployment, particularly on devices with limited computational resources. Enter quantization, a technique that has risen to prominence as a means of optimizing LLMs for efficient inference. GGML (Generic GEMM Library), a cutting-edge C library developed by Georgi Gerganov, stands at the forefront of this optimization, offering innovative quantization methods that enhance model performance without compromising on accuracy.
The Necessity for Quantization in LLMs
Quantization operates on the principle of reducing the numerical precision of the model’s weights, thereby minimizing memory consumption and accelerating inference times. This is not merely a matter of efficiency; it’s a necessity for the practical deployment of LLMs, especially on consumer hardware that may lack the high-end GPUs typically used in data centers.
GGML: A Foundation for Optimized Machine Learning
GGML is more than a library; it’s a comprehensive toolkit designed to streamline the deployment of LLMs. It provides the foundational elements for machine learning operations, such as tensors, and extends its capabilities with a unique binary format, GGUF, for distributing and storing LLMs. The GGUF format is extensible and future-proof, ensuring that new features can be added without breaking compatibility with existing models.
Quantization Methods in GGML
GGML supports a variety of quantization methods, each tailored to different trade-offs between model accuracy and computational efficiency:
- q4_0: A standard 4-bit quantization method that offers a good balance between size and performance.
- q4_k_m: A mixed-precision approach that applies higher precision to certain layers, such as attention.wv and feed_forward.w2, to maintain accuracy while reducing the overall model size.
- q5_k_m: This method further increases precision for critical layers, providing higher accuracy at the cost of increased resource usage and potentially slower inference.
Practical Quantization with GGML
The process of quantization with GGML is both sophisticated and practical. It begins with converting the model’s weights into GGML’s FP16 format, followed by the application of the chosen quantization method. This conversion can be executed on platforms like Google Colab, leveraging their free GPU resources to facilitate the process.
Efficient Inference with llama.cpp
The llama.cpp library, also developed by Georgi Gerganov, is a critical component in the deployment of quantized models. Written in C/C++, it is designed for efficient inference of Llama models on both CPUs and GPUs. This dual-compatibility makes it an ideal tool for deploying models across a wide range of devices.
Quantization and CPU Inference
One of the most significant advantages of the GGML and llama.cpp combination is their ability to enable efficient CPU-based inference. By offloading some layers to the GPU where possible, or relying solely on the CPU for inference, these tools make it feasible to run LLMs on devices that may not have the latest GPU technology.
Technical Insights into Quantization
At its core, GGML’s quantization process involves grouping weights into blocks and applying a quantization scheme that reduces their precision. For example, the Q4_K_M method might store most weights at 4-bit precision while reserving higher precision for specific layers. Each block of weights is processed to derive a scale factor, which is then used to quantize the weights efficiently.
Comparative Analysis of Quantization Techniques
When evaluating the performance of GGML’s quantization against other methods like NF4 and GPTQ, it shows a competitive edge in terms of perplexity — a measure of how well a model predicts its own test data. While the differences may be subtle, they can be significant when considering the trade-offs between model size, inference speed, and accuracy.
The Future of Quantization in Machine Learning
Quantization is more than a passing trend; it is a transformative approach that is set to redefine how machine learning models are deployed. As the technology matures, we can expect to see further improvements in mixed-precision quantization and other advanced techniques that will push the boundaries of what is possible with LLMs.
Conclusion
GGML’s quantization techniques are a testament to the potential for optimizing machine learning models for efficiency without sacrificing performance. By enabling the deployment of large models on devices with limited resources, GGML is helping to democratize access to advanced machine learning capabilities. As the field of machine learning continues to evolve, the role of GGML and libraries like it will be pivotal in shaping the future of model deployment, ensuring that the benefits of LLMs can be fully realized across a diverse array of applications and environments.
In summary, GGML and its associated tools like llama.cpp are not just optimizing the present state of machine learning models; they are setting the stage for a future where the deployment of sophisticated LLMs is as accessible and efficient as possible. With continued advancements in quantization techniques, the gap between research and practical application will continue to narrow, bringing us closer to a world where the full potential of machine learning can be harnessed by all.