How does StarLandAI Control LLM Output Format?


Large language models can produce text; however, they might not always follow directions correctly when a specific output format is required. In the process of creating characters at StarLandAI, it is necessary to extract key character attributes from multiple messages input by the user to generate structured character attribute information. The ability to accurately generate outputs that meet the required format influences the user experience in configuring character attributes through StarLandAI. Different strategies for designing prompts have been developed to enhance the consistency and reliability of the text produced, yet these methods do not always prove adequate. So, how to control the LLM output format?
StarLandAI uses lm-format-enforcer [1] to solve the issues. By restricting the selection of tokens the language model can produce at each step, lm-format-enforcer ensures compliance with the desired output format, while simultaneously reducing constraints on the language model’s capabilities.
1. How does it work?
lm-format-enforcer works by integrating a character-level parser with a tokenizer prefix tree to create an intelligent token filtration system.
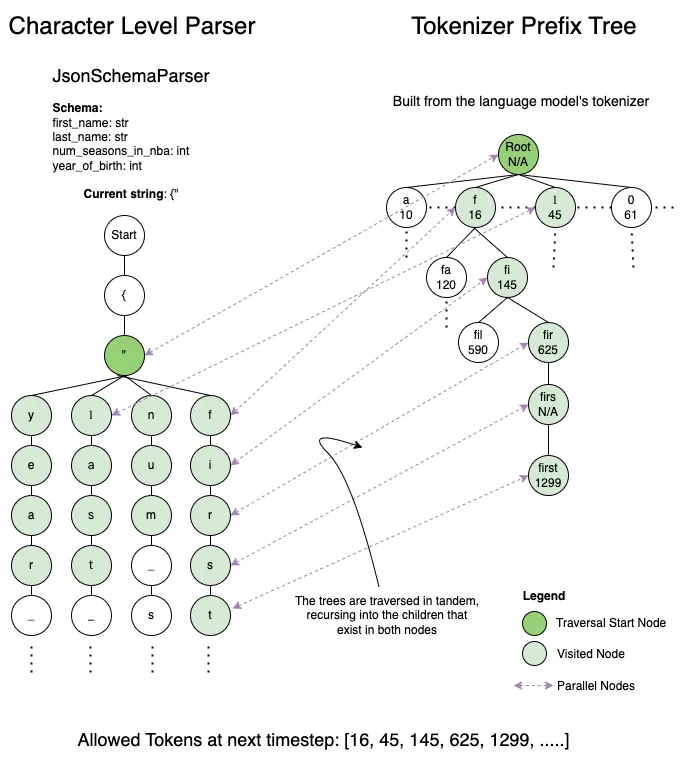
(1) Character Level Parser
Interpreting a string into any given format could be perceived as a tacit tree structure — during any point of the parsing sequence, there exists a specific selection of permissible subsequent characters, which, upon being chosen, lead to a subsequent range of allowable characters, and this pattern continues.
(2) Tokenizer Prefix Tree
If we have a tokenizer from a particular language model, we are able to construct a prefix tree with all potential tokens the model might produce by creating all conceivable token sequences and incorporating them into the tree.
(3) Combining the two
With a character-level parser and a tokenizer prefix tree in hand, we can adeptly and effectively sift through the permissible tokens for the language model to produce in the next step: We navigate only through those characters that are concurrently present in the node of the character-level parser as well as the node of the tokenizer prefix tree. This allows us to find all of the tokens. This process is repeated recursively on both trees, culminating in the retrieval of all permissible tokens. As the language model outputs a token, we update the character-level parser with the newly generated characters, preparing it to refine the options for the upcoming timestep.
2. Achieved effect
By applying this technique, StarLandAI is able to enforce the generation of specific enumerated values by the LLM. For example, when categorizing user-created characters and generating recommended character tags through the LLM, StarLandAI utilizes regular expressions to describe the list of tags that the LLM can generate. Then, it converts the regular expression into a character-level parser. This parser is applied to process the LLM’s output logits, filtering out any subsequent tokens that violate the regular expression. Through this method, the LLM selects the next token with the highest probability from those that conform to the regular expression.

3. Feature in StarLandAI
On StarLandAI, configuring a custom character doesn’t require users to fill out extensive and complex forms, nor is there a need to understand the significance behind each field. Users simply need to have a casual chat with the Starland assistant, informing Starland of the character they wish to create. Starland itself handles the extraction and completion of the form attributes.
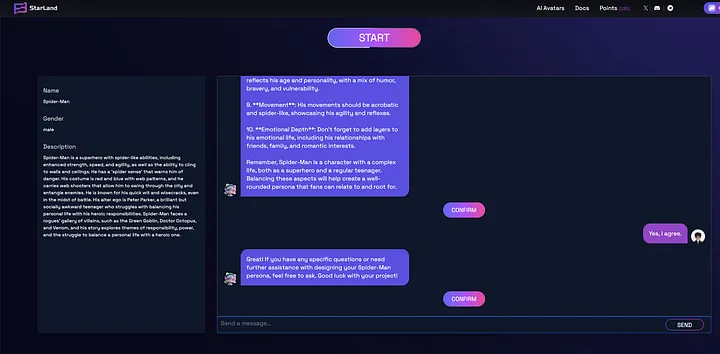
Yes, Starland utilizes the lm-format-enforcer in the feature that allows users to configure custom roles. Through conversation with users, Starland understands the type of character a user wishes to create. It then leverages LLM to offer inspiring suggestions and assistance for the user’s configured character. Finally, it summarizes the entire conversation history to generate a structured custom role configuration. Just like that, a custom character is configured.